



基于GAS变换和PCANet的XRF-visNIR土壤重金属超标分析新进展 发布日期:2024-08-01 18:37:26 文章来源:Tecsync(泰克鑫科)智能制造 探索微观世界,解析万物之本
TECSYNC
基于GAS变换和PCANet的XRF-visNIR土壤重金属超标分析新进展
01.研究背景
X射线荧光(XRF)和可见光-近红外光谱(visNIR)因其非破坏性和快速性,已成为评估土壤中各种参数和污染物极具前景的方法。对于土壤中重金属的分类和估算,XRF和visNIR的融合已经得到了广泛研究,并取得了高度准确的分类和估算结果。然而,当融合数据集中包含光谱数据过多的情况下,传统的分类模型在对于具有多个变量的高维XRF-visNIR光谱分类任务上表现不佳。
在光谱分类领域,深度学习模型在处理复杂分类问题方面取得了显著成功。研究表明,这些模型在准确性方面优于传统机器学习方法。在处理XRF-visNIR融合数据时,一维卷积神经网络(CNN)已成为强大的工具。然而,直接应用CNN可能导致信息丢失和无法捕获特征波长之间的关系。为了解决深度学习中的特征提取问题,研究人员提出了几种改进方法。例如,多尺度卷积神经网络引入不同尺度的卷积核,以捕获光谱数据在不同尺度上的波长特征。另一方面,自编码器可以通过学习数据的潜在表示来提取更有价值的特征。在现有研究的基础上,本研究旨在将深度学习网络应用于XRF-visNIR融合模型。为了应对非统一维度融合和无法保留波长特征的挑战,本研究设计了一种Gramian Angular Summation(GAS)方法,用于将一维光谱数据转换为二维图像。将XRF和visNIR作为RGB通道输入,从而将它们融合成一张新的图像。为了克服大数据冗余和特征提取困难的问题,本研究采用PCANet网络从图像中提取特征,通过利用深度学习网络、GAS 和 PCANet为土壤重金属污染的快速筛选提供了新的视角。
02.创新研究
2.1样品采集和XRF光谱采集
在清镇市红枫湖盆地采集了180个土壤样品。将土壤样品分别利用Tecsync公司制造的手持式XRF光谱仪和可见光-近红外光谱(vis-NIR)进行光谱分析。对于XRF光谱,在45 kV管电压、25 mA电流、90 s测量时间采集XRF光谱数据。对于vis-NIR光谱,光谱范围为350至2500纳米,采样间隔为1.4纳米(350-1000纳米)和2纳米(1000-2500纳米),重采样间隔为1纳米。
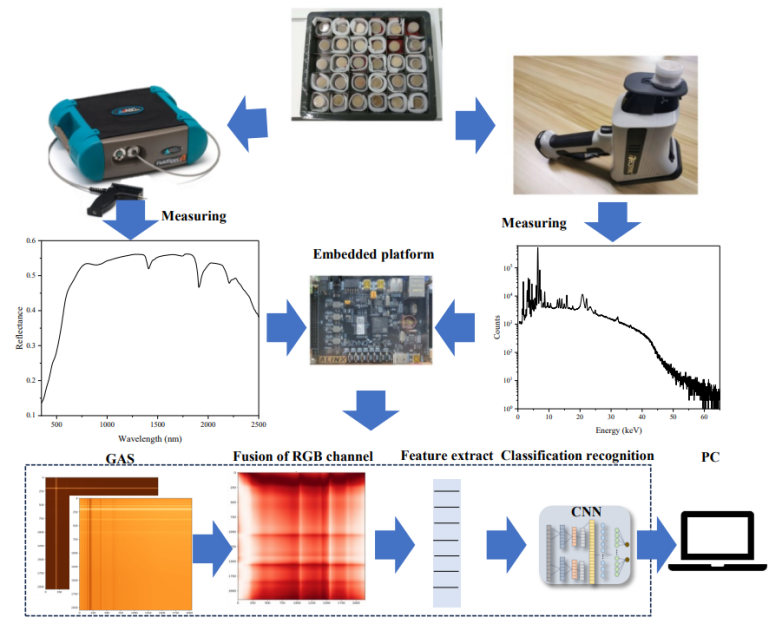
图1 数据采集及全文流程图
2.2 PCANet-CNN网络设计
在基于XRF-visNIR光谱的土壤重金属污染风险筛选任务中,采用CNN模型进行二元分类,结果为“是”或“否”。如果土壤样品中的元素浓度超过了风险筛选阈值,则认为存在重金属污染的风险。根据《中国农田土壤污染风险筛选值暂行技术规定》,筛选选择标准为pH≤5.5,与180个样品中168个的土壤pH值一致。其余12个样本的pH值均小于6.04。例如,在元素Pb的情况下,大于70 mg/kg的浓度标记为1,而小于或等于阈值的浓度标记为0。编码和建模过程如图2A所示。在样本选择过程中,选取红枫湖四个湖区的样本作为训练集和测试集,选取离红枫湖较远的样本作为独立验证集。
为了提供模型的全面比较,传统的1D-CNN和XGBoost模型分别使用预处理后的XRF和visNIR光谱构建,并使用数据融合方法。此外,通过结合RGB的GASF和GADF图像作为CNN的输入,建立了GASF_CNN和GADF_CNN模型。此外,采用PCANet特征提取方法建立GASF_PCANet_CNN和GADF_PCANet_CNN模型。共建立了6个分类模型,并对这些模型进行了全面的评价和分析。1D-CNN模型的结构如图2b所示。构建了10层结构,包括输入层、卷积层1、池化层1、卷积层2、池化层2、卷积层3、池化层3、全连接层1、全连接层2、输出层。
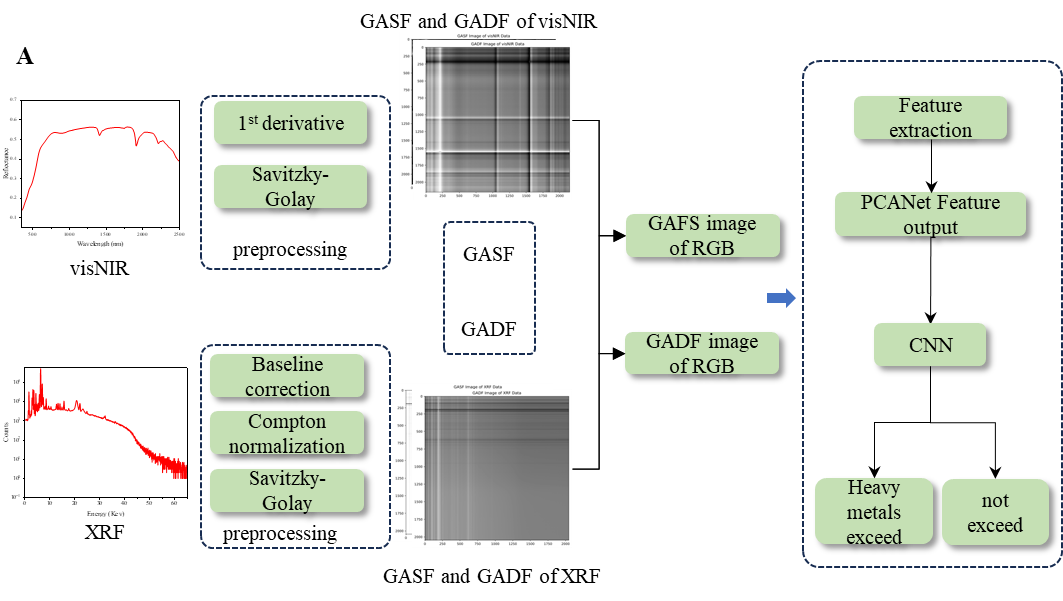

图2 a) GAS结合PCANet和CNN对土壤重金属进行分类;b) 1D-CNN网络
2.3 PCANet模型的参数设计
为了探究不同 PatchSize 对模型性能的影响并选择最佳 PatchSize,进行了以下实验。实验使用了四种不同的 PatchSize:3x3、5x5、7x7 和 9x9。训练并比较了 PCANet 和 CNN 模型的性能,如图3所示。在 3x3 PatchSize 下,PCANet 的训练时间为 18.56 秒,其在训练集和测试集上的识别率分别为 83.93% 和 79.76%。当 PatchSize 增加到 5x5 时,PCANet 的训练时间增加到 23.18 秒,但识别率分别下降到 79.46% 和 76.19%。随着 PatchSize 继续增加到 7x7 和 9x9,出现了相同的趋势。
这些实验结果揭示了一个重要现象:随着 PatchSize 的增加,尽管模型的训练时间增加,但识别率并没有提高,反而呈现下降趋势。这可能是因为增加 PatchSize 实际上增加了模型的复杂性,导致过度复杂化,从而影响了结果。基于上述分析,在设计 PCANet 模型的参数时,需要在实现高识别率和确保较短训练时间之间找到平衡。这需要根据具体应用需求和实际情况合理设置和调整参数,如 PatchSize。在本次建模中,选择 3x3 的 PatchSize 以实现最佳的模型性能。
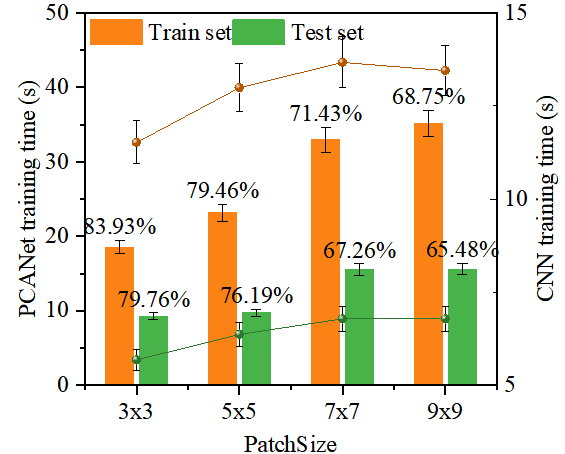
图3 不同 PatchSize对PCANet 和 CNN 模型性能的影响
在建立 XRF-visNIR 重金属分类模型时,选择适当的 NumFilters 值至关重要。我们将 NumFilters 设置为 2、4、6 和 8,并进行了三次独立实验,其中训练集和测试集随机划分。计算了 PCANet 和 CNN 的训练时间,以及测试集和训练集的识别率。实验结果如图4所示,误差条以标准差表示。根据结果分析发现,NumFilters 值的增加对模型性能有一定影响。随着 NumFilters 的增加,PCANet 的训练时间逐渐增加。当 NumFilters 为 2 时,PCANet 的训练时间为 18.32 秒,而当 NumFilters 为 8 时,训练时间增加到 35.14 秒。这表明随着 NumFilters 的增加,训练时间也相应增加。同样,随着 NumFilters 的增加,CNN 的训练时间也逐渐增加。当 NumFilters 为 2 时,CNN 的训练时间为 11.52 秒,而当 NumFilters 为 8 时,训练时间增加到 13.45 秒。
在识别率方面,当 NumFilters 为 4 时,达到了最高识别率 85.42%。当 NumFilters 增加或减少时,识别率呈现不同程度的下降。在我们的实验数据中,当 NumFilters 为 6 时,识别率为 79.88%。综上所述,我们建议选择 NumFilters 为 4 的参数组合。这一组合在识别率方面达到了最佳效果,并且相对较短的训练时间使其更加实用。
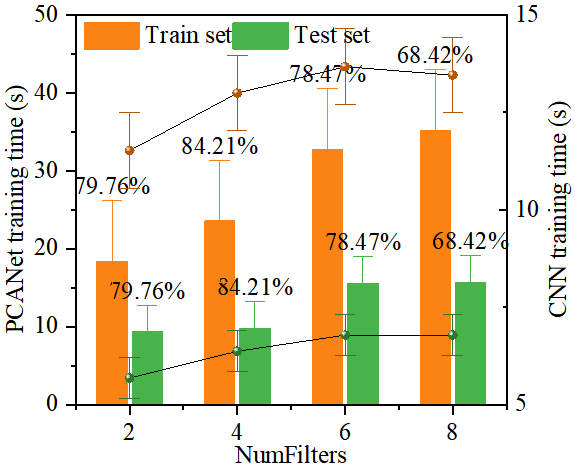
图4 不同 NumFilters数量对PCANet 和 CNN 模型性能的影响
此外,我们基于数据分析研究了不同 BlkOverLapRatio 值对 PCANet 模型性能的影响。为了分析 BlkOverLapRatio 对 PCANet 模型的影响,我们使用土壤数据集进行了一系列实验。数据集被分为训练集和测试集,并在不同的 BlkOverLapRatio 值下训练和测试 PCANet 模型(见图 5)。我们可以观察到以下趋势:随着 BlkOverLapRatio 的增加,PCANet 模型的训练时间逐渐增加。例如,当 BlkOverLapRatio 为 0.00 时,PCANet 在训练集上的训练时间为 8.08 秒,而当 BlkOverLapRatio 增加到 0.70 时,训练时间增加到 28.04 秒。同样,CNN 的训练时间也随着 BlkOverLapRatio 的增加而增加。在识别率方面,我们注意到当 BlkOverLapRatio 为 0.00 时,训练集上的最高识别率为 87.50%。然而,随着 BlkOverLapRatio 的增加,识别率略有下降。例如,当 BlkOverLapRatio 为 0.70 时,训练集上的识别率为 85.42%。因此,在我的模型中,选择 BlkOverLapRatio 为 0.4。
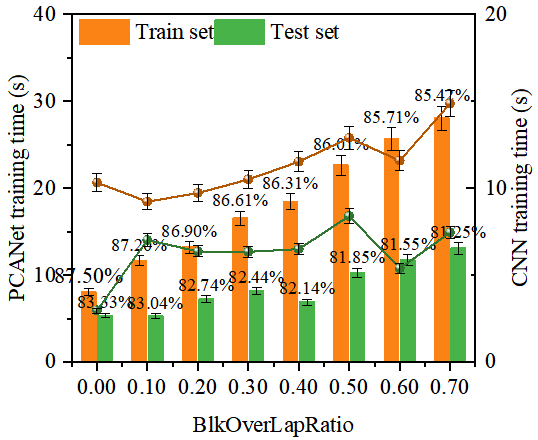
图5 不同 BlkOverLapRatio 值对PCANet 和 CNN 模型性能的影响
局部直方图块的大小直接影响 PCANet 模型提取特征的表达。为了确定最合适的 HistBlockSize(N1 × N2),进行了三次独立实验,使用不同的 N1 = 2, 4, 6, 8, 10, 12 和 N2 = 2, 4, 6, 8, 10, 12。计算了每次实验的平均识别率和模型时间成本。首先,观察 HistBlockSize 对训练集样本识别率的影响,如图 6 所示。可以看到,随着 HistBlockSize 的增加,总体识别率呈下降趋势。特别是,当 HistBlockSize N1×N2 = 6 × 12 时,平均识别率最高,可达 91.25%;而当 N1×N2 = 2 × 12 时,平均识别率最低,仅为 72.58%。此外,观察 HistBlockSize 对测试集识别率的影响,如图6所示。当 N1×N2 = 6 × 12 时,平均识别率最高,可达 90.30%;而当 N1×N2 = 6 × 4 时,平均识别率最低,仅为 74.68%。通过分析不同 HistBlockSize 下识别率的热图,我们选择将 HistBlockSize 设置为 6 × 12 以实现最佳识别效果。
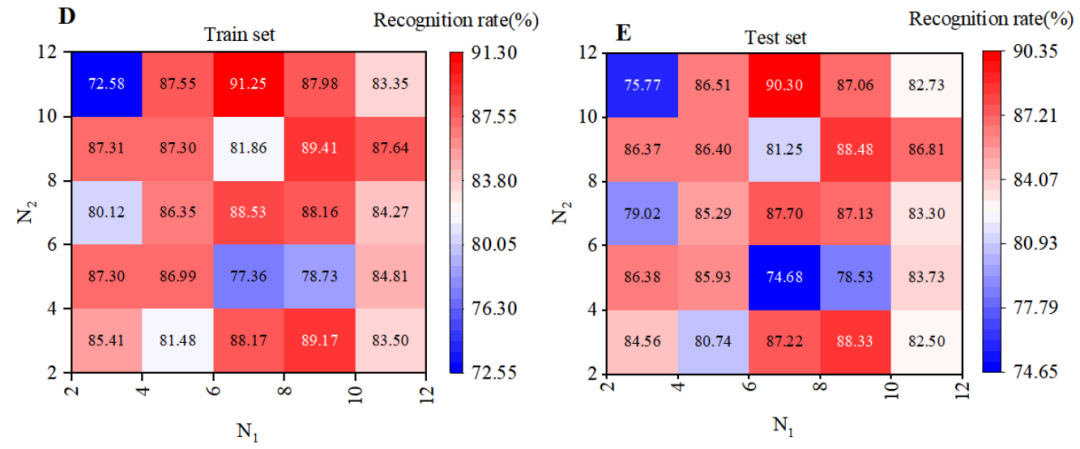
图6 不同 NumFilters数量对PCANet 和 CNN 模型性能的影响
2.4 XRF土壤重金属超标分析
本研究对多种模型进行了综合比较,包括 1D-CNN、RF、KNN、SVM、XGBoost、MLP、GBDT、GASF_CNN、GADS_CNN、GASF_PCANet_CNN和 GADS_PCANet_CNN,用于重金属的预测,准确率、召回率、精确率和 F1 分数结果如图7所示。
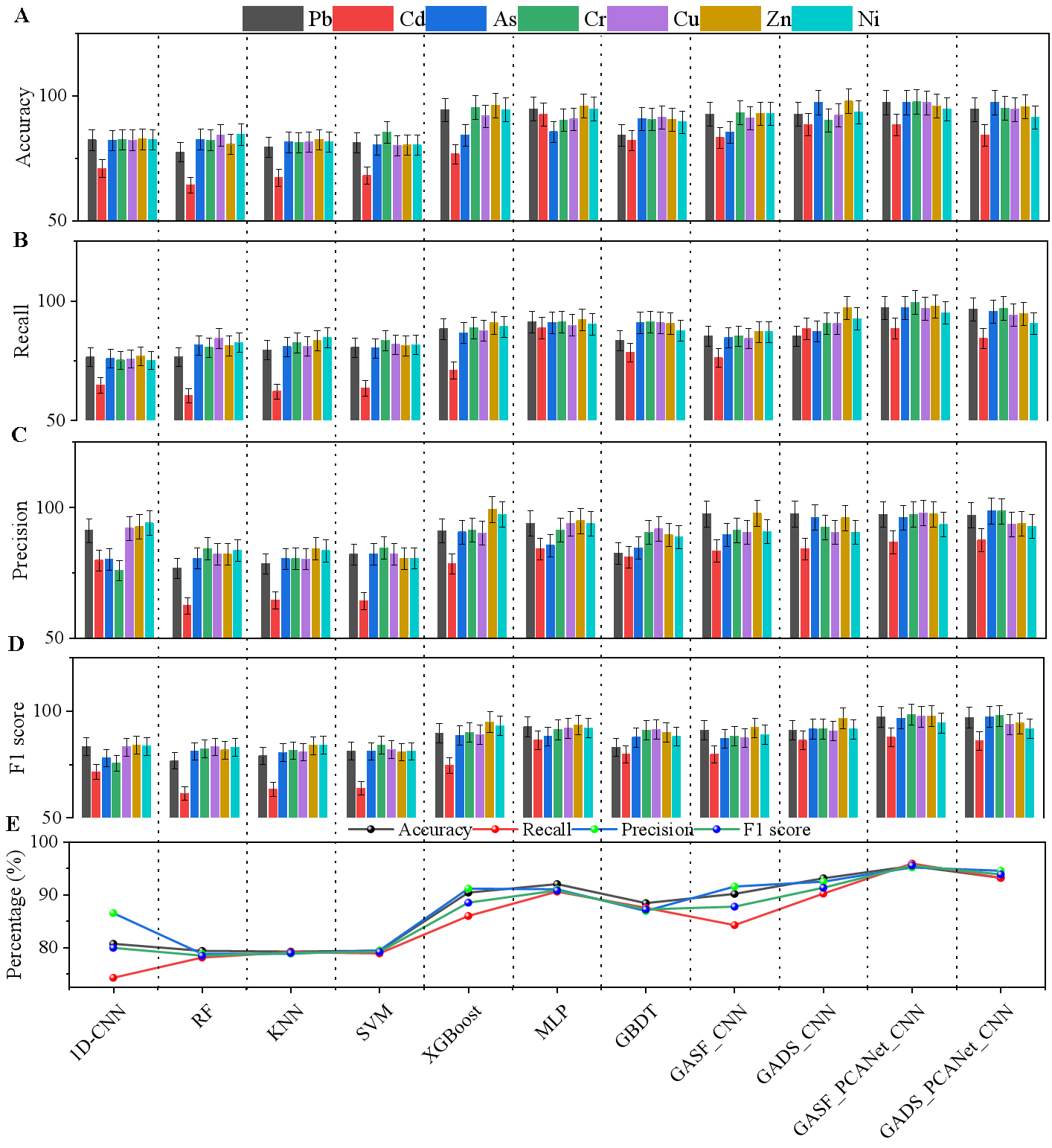
图7 不同重金属元素的测试集模型性能比较
1D-CNN的准确率、召回率、精确率和 F1 分数在不同重金属中范围为 64.84% 至 94.00%。RF 模型的性能参数范围为 64.31% 至 84.54%。1D-CNN 和 RF 算法可能不适合变量数量较多(超过 4000)的建模条件。在分类之前,还需要对大量数据进行必要的特征提取。与传统机器学习算法如 SVM 和 KNN 相比,XGBoost、MLP 和 GBDT 表现更佳。这些集成机器学习方法在各种重金属分类任务中表现出良好的性能。其中,XGBoost 模型具有稍高的平均准确率和平均精确率,MLP 模型具有稍高的平均召回率,GBDT 模型具有稍低的平均 F1 分数。
GASF_CNN、GADS_CNN、GASF_PCANet_CNN 和 GADS_PCANet_CNN 表现出色。每个模型在不同的重金属分类任务中均取得了相对较高的准确率、召回率、精确率和 F1 分数。在 Pb 和 Cd 分类任务中,CASF_PCANet_CNN 表现良好。然而,该模型对 Cd 的识别表现一般,平均准确率为 87.77%,这可能归因于 Cd 含量较低。为了提高 Cd 的识别,可能需要进行硬件改进或增加测试时间。在 As 和 Zn 分类任务中,GADS_CNN 表现出色。Zn 具有较高的风险筛选值,一般模型可以实现良好的识别。对于其他重金属,各模型的表现有所不同。
我们将使用训练和测试数据集训练的模型部署在嵌入式平台上,并在独立验证区域进行了快速验证,获得的结果如图 7E 所示。模型的表现与训练和测试数据集的一致。GASF_CNN、GADS_CNN、GASF_PCANet_CNN 和 GADS_PCANet_CNN 模型继续表现最佳。在七个重金属分类模型中,GASF_CNN、GADS_CNN、GASF_PCANet_CNN 和 GADS_PCANet_CNN 仍然取得了良好的结果。可以观察到,将 GAS 转换与深度学习网络结合比机器学习表现更好。从性能角度来看,GASF_PCANet_CNN 模型在独立验证区域表现出色。基于模型分析,我们推荐 GASF_PCANet_CNN 作为 XRF-visNIR 领域中重金属分析的最合适建模方法。该模型在本研究中针对所有评估的重金属均始终实现了高准确率、召回率、精确率和 F1 分数,对大多数重金属(包括 Pb、Cd、As、Cr、Cu、Zn 和 Ni)的 F1 分数在 97%左右。
03.应用与展望
本研究探讨了将XRF-visNIR光谱数据、Gram角场变换、PCANet网络特征提取和CNN结合用于重金属筛选的方法。通过GAF将XRF和visNIR转换为二维图像,然后将其融合成RGB图像。然后,提利用PCANet网络提取特征,该网络可以对高维GAF数据进行降维和特征提取,有效地最小化数据量。最后,将数据输入到CNN中进行模型训练并识别土壤中重金属是否超标,提高了识别和分类的准确性。与XGBoost等方法相比,本研究提出的方法可以提高Pb、Cd、As、Cr、Cu、Zn、Ni等7种重金属的分类性能,为土壤污染监测和管理提供了一种可行的解决方案。


服务热线|4000-988-166
联系电话|133-7683-5869
联系微信|tecsync_sale
(PS:发送时请备注公司或合作项目哦)

